Analysing normative data
Introduction
In order to be able to present object at locations with a range of expectancy values, which is crucial to show that this has U-shaped relationship, I asked six member of my research group. to rate all combinations of objects and location that exist in the virtual environment for the schemaVR task. There were twenty possible objects and twenty possible locations (i.e. 400 object/location ratings in total).
After the completing these ratings, the participants were asked to rate the overall expectancy of those objects for a kitchen. In both cases, the scale ranged from -100 (unexpected) to 100 (expected) and was continuous. Here I will visualise and interpret the results. The code for the task can be found https://github.com/JAQuent/ratingStudy.
Used libraries and functions
|
|
Loading the rating data
I start with loading the data and creating a 20 x 20 x N matrix holding all 400 location ratings for all participants. Similarly, I create a 20 x N matrix to hold the 20 objects ratings. After that, I shuffle the data because people in the group could otherwise infer the identity of the other participants.
|
|
After successfully loading the data and saving it in the matrices, I want to look at distribution of the location ratings. I collapse the data across all 6 participants and create a histogram:
|
|
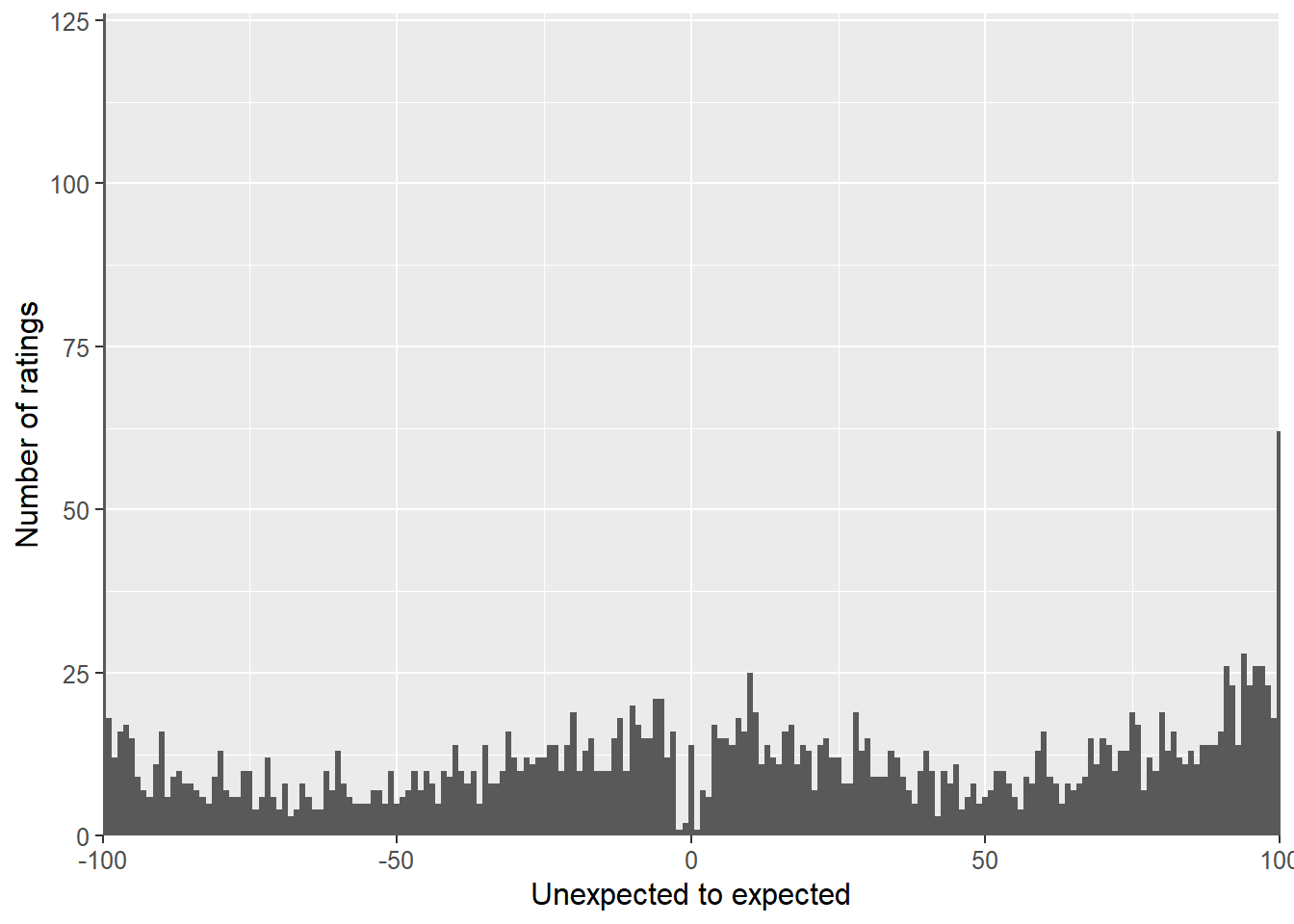
The ratings are indeed spread across the whole scale, which is good. However it is also interesting to look at the individual distributions. There were I plot one histograms for each participant.
|
|
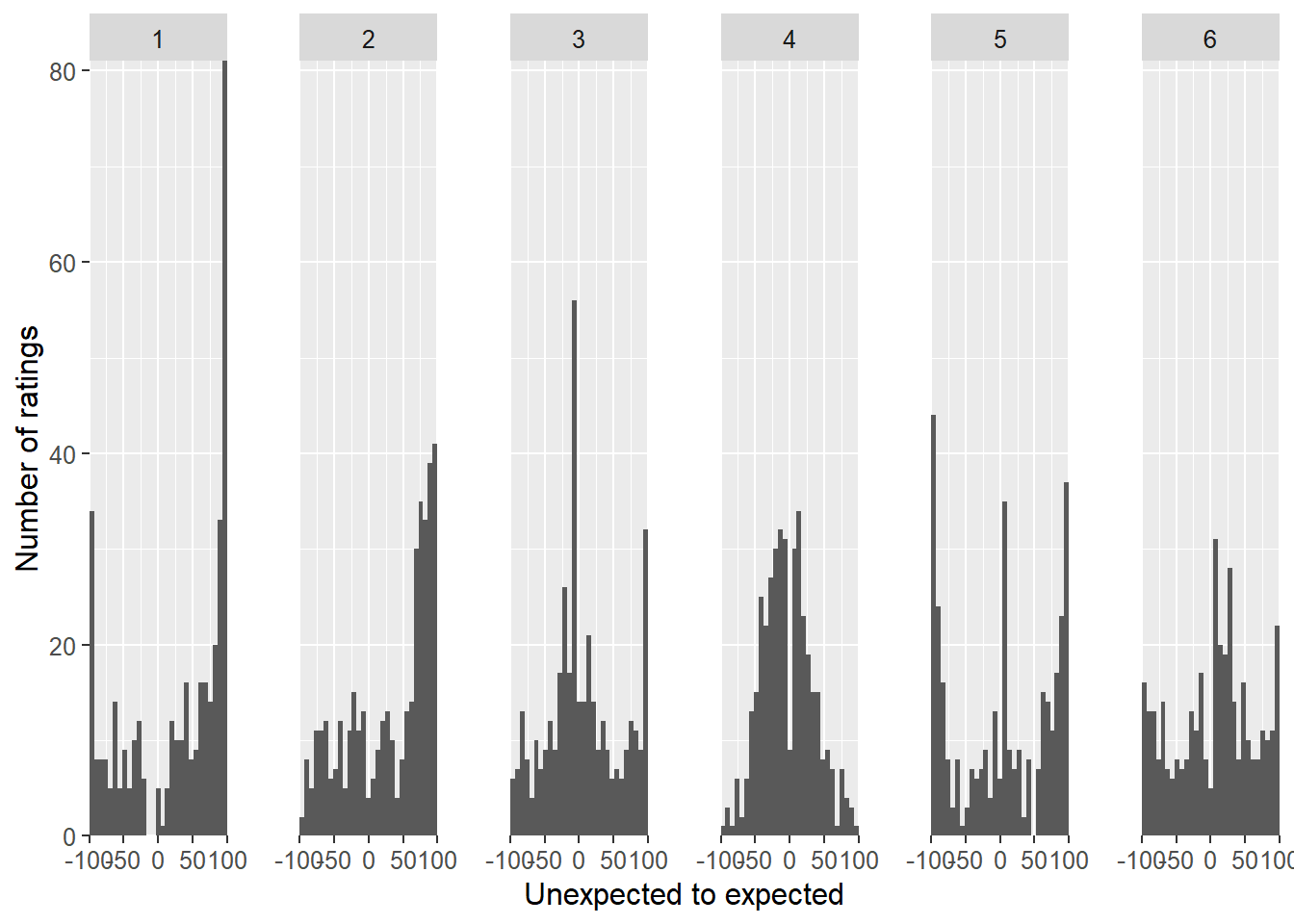
Looking at the individual data, it is quite apparent that the distributions differ quite profoundly in terms how their responses are spread. On looks a bit Gaussian with a small dip around zero, while other distributions tended to include many extreme responses.
As I want to use this data to create a distribution to draw a combination of objects and locations from, I average the matrices and calculate the standard deviations to have an idea how the raters differed from each other. Here you can see the heatmaps:
|
|
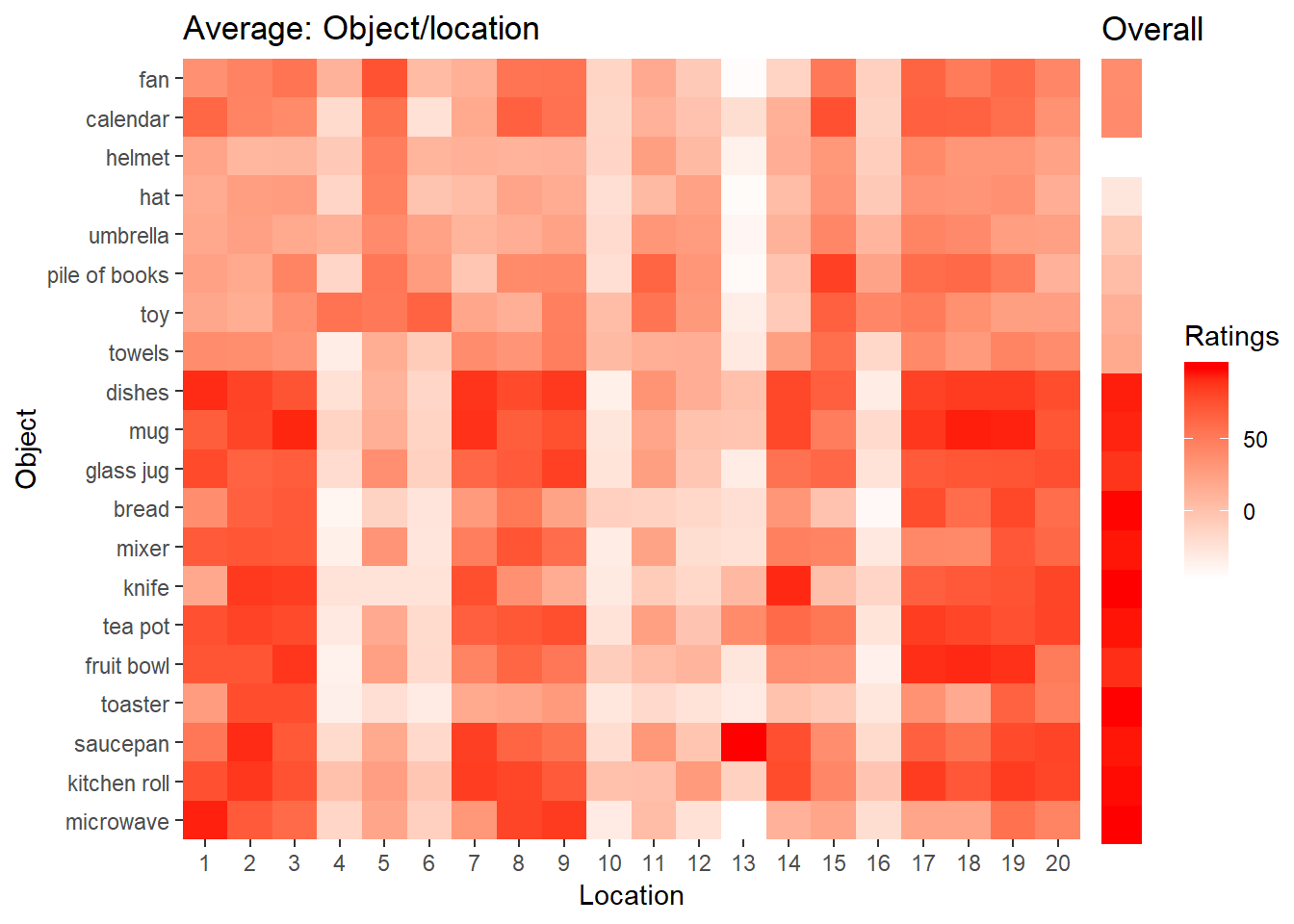
The first twelve objects (from microwave to dishes) are supposed to be expected in a kitchen. This is also visible in the heatmaps both in the heatmap showing the average ratings for every object/location combination and in the overall heatmap showing the average ratings for the overall expectancy of a particular object in kitchen. From the white vertical stripes, it is also apparent that no object is really expected for some locations. One of those location for instance is on the floor in a corner of the room.
|
|
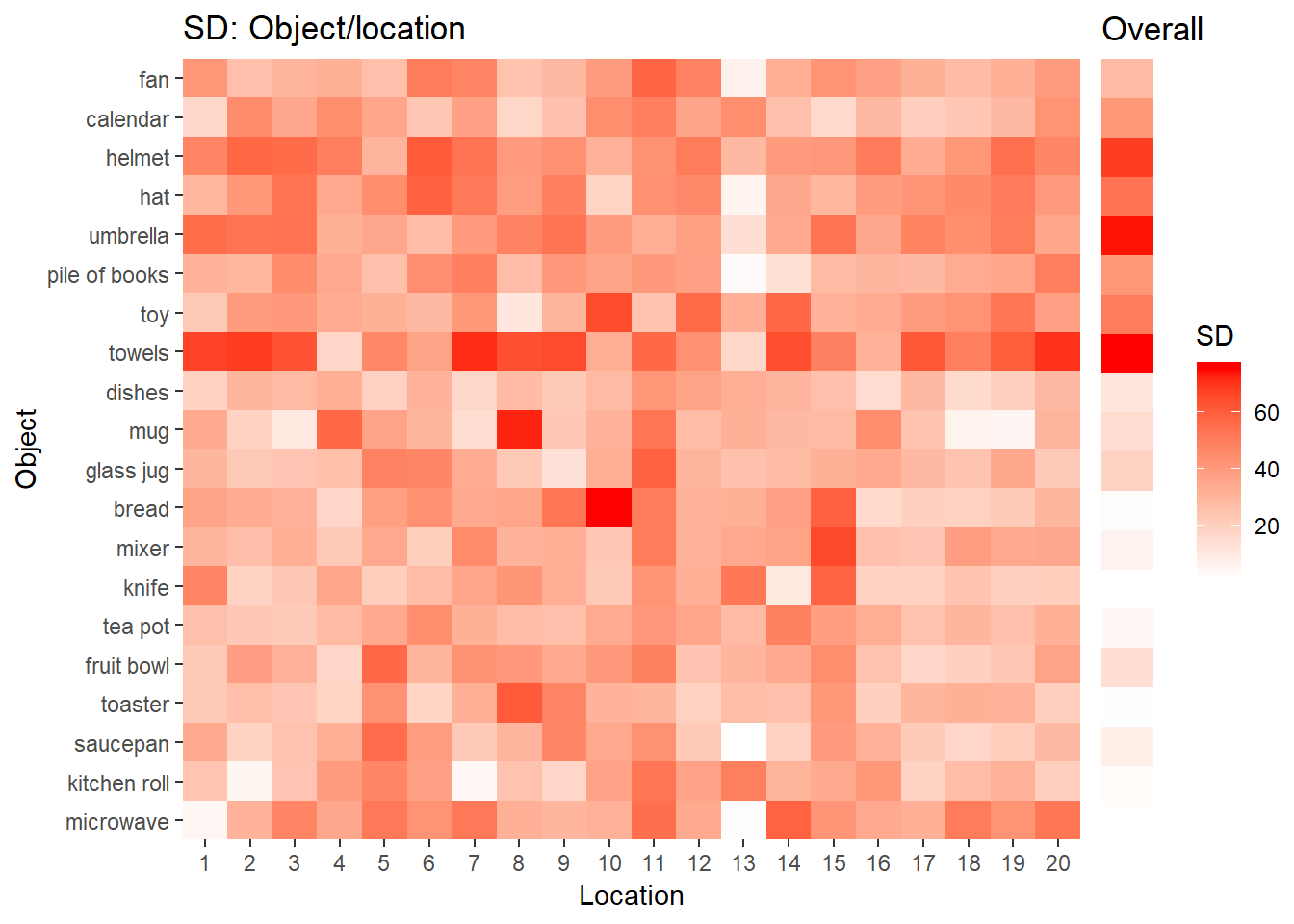
The SD are quite high in general. This stems from the fact that participants seem to have used difference response criterions. It is notable there is a lot of disagreement among the participant with regard to expectancy of the towel. This definitely needs more attention and I am considering not to use the towels.
Finally, I am also interest to see whether there is a relationship between the average expectancy across all locations and the overall expectancy rated at the end of the experiment.
|
|
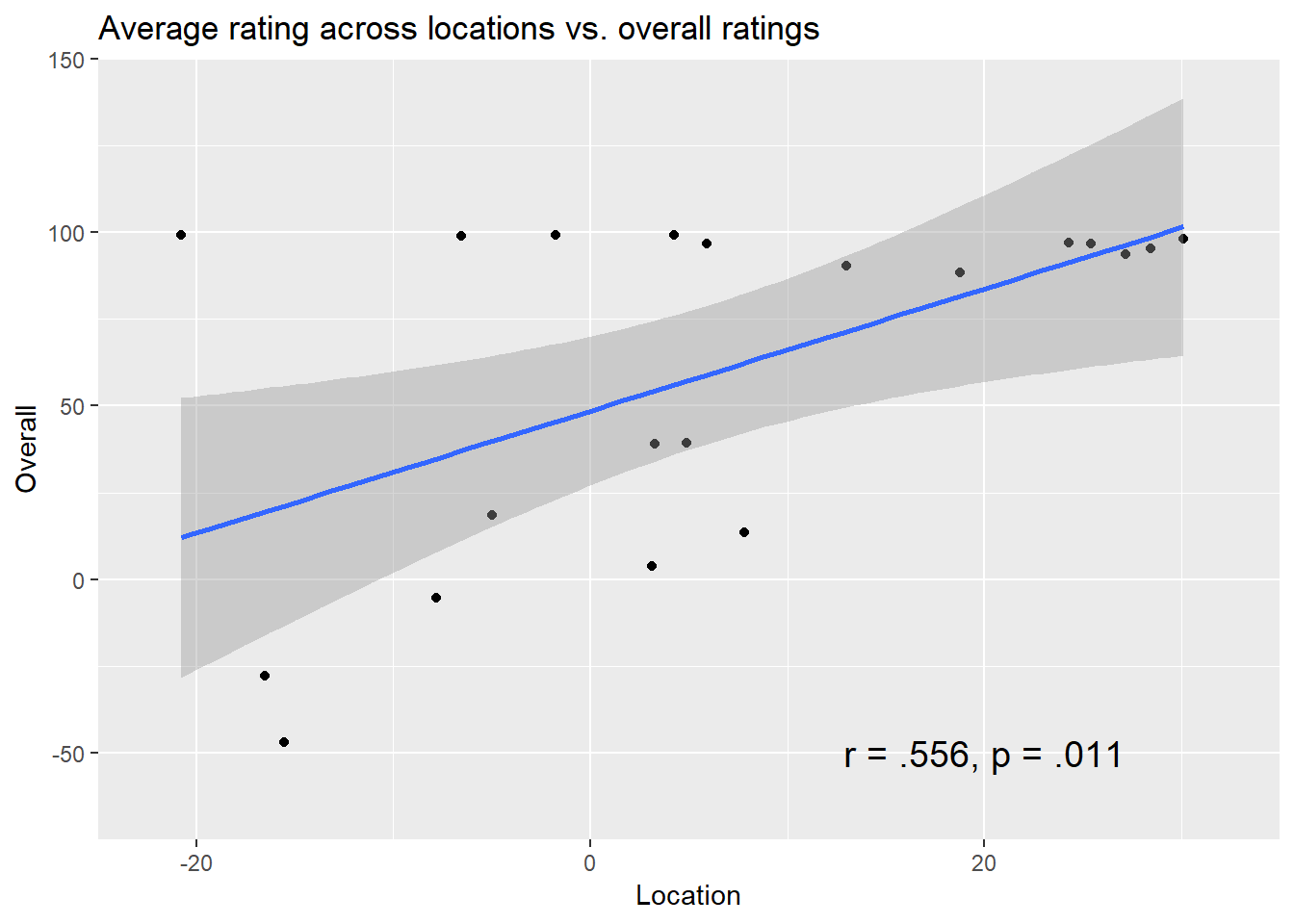
As it turns out, there is a significant positive correlation between the average ratings across locations and the overall ratings r, r = .556, p = .011.